unicode_grep.app — an AppleScript droplet
Version 0.7 (2011-07-10)
Introduction
Mac OS X lacks a good search program for text contents of files. The only utility available system-wide, Spotlight, is not accurate enough for text content search. The best search program for Classic Mac OS, MgrepApp worked on the Classic environment of OS X; but it no longer work on Intel-Mac...! However, Mac OS X comes with a very powerful and fast searching utility which is Unix grep, but you have to use Terminal to use it, and this is not easy at all. On the other hand, grep can only search in UTF-8 text files.
Therefore, I wrote an AppleScript droplet which will convert all files in a folder into UTF-8 files (please see my other page Batch Convert Files to UTF-8). Here I present another AppleScript droplet which can be used as an interface for grep. Used in combination with Jedit X, this droplet can simulate to a certain extent the behavior of MgrepApp: you will get a list of result in Jedit X; selecting one of the lines, and choosing a macro in Jedit X, you will be able to open the desired file and select the line where the target word is found.
Jedit X is a very powerful shareware text editor (2940 yen or $28) that can handle styled text.
I assume in this ReadMe that we are using unicode_grep.app for search words in CBETA Taisho text files, and will take examples for this kind of use.
Requirements, Contents of the package and How to install:
Requirements:
1. OS X 104 and later
2. Jedit X -- (the demo version, working for one month, can be downloaded free of charge...)
3. a bunch of folders containing UTF-8 text files
Contents:
When expanded, the package that you will download from this page (see at the bottom of the page) will contain:
• unicode_grep_AppleScript/
• unicode_grep_ReadMe.rtf this file
• grep_symlinks_folder an empty folder
• unicode_grep.app
• Put_in_App_script_folder/
• open_file_fromGrepRes.scpt
• T01 A folder containing 98 utf-8 files, downloaded from <http://w3.cbeta.org/>
How to install:
To use the Jedit X macro named open_file_fromGrepRes for Jedit X, you have to copy them in its "Scripts" folder.
1. Launch Jedit X, and select Window > Script Window or Macros > Show Script Window in Jedit X to display the Script window.
2. Click on the Macro Menu tab of the Script window;
3. Drag the script open_file_fromGrepRes.scpt in the folder Put_in_App_script_folder from the Finder to the desired location in the Script window to save it there.
4. You will be asked which you want to copy the script file or the alias file. You would click on Copy, and the script file will automatically be saved in the following scripts folder:
/Users/[your_account]/Library/Application Support/Jedit X/scripts/
5. You must set the default file encoding of Jedit X to Unicode (UTF-8) at this moment:
Choose the menu-item Jedit X > Preferences; press the icon Encoding at the top of the window; set the pop-up menu under Default Encoding and Line Endings for Plain Text to Unicode (UTF-8) (and the Line Endings to Unix (lf)).
For details, you can refer to Jedit X's help: Chapter 11.2: "Script Window", and Chapter 2.4: "Encoding".
After you have installed this script for Jedit X, you can place the folder unicode_grep_AppleScript anywhere you want (preferably on your desktop? — or you can put an alias of unicode_grep.app on your Deaktop), but you should NOT change the structure of this folder. Especially, unicode_grep.app and the folder named grep_symlinks_folder must be in the same folder.
How to use:
To see how unicode_grep.app works, first, make sure that you have all the needed pieces:
• Jedit X
• one or a bunch of folders full of text files in UTF-8 -- for example, a folder named "T01", containing all the files of volume 1 of the Taisho Canon.
-- Hereafter, I will take this folder as example.and of course
• unicode_grep.app
Here are the basic steps:
1. Launch Jedit X, then return to the Finder.
2. Drag and drop your folder "T01" onto the icon of unicode_grep.app.
3. A dialog will appear, asking you to enter a search word.
4. Enter for example "大自在" (without quotes)
5. Almost immediately a new untitled window will open in Jedit X, with the result of the grep search:
Found 2 occurences...
/Volumes/my_volume/cbeta/app1/T01/T01n0022.txt:403:T01n0022_p0275b07(03)║其行平等。尊大自在。心念無畏。以一身化無數身。
/Volumes/my_volume/cbeta/app1/T01/T01n0081.txt:415:T01n0081_p0900a17(04)║七衣服鮮潔。八臥具細軟。九得大自在。十命終生天。
As you see, each line of the result is composed of three elements: a) the file path, followed by a “:”, followed by b) the line number, followed by a “:”, and the actual line. In fact, this can be a weak point of this script, because there may be file names which contain elements such as “:” followed by a number, followed by a “:”... I only hope that you do not have too many such files.6. You can select one of the lines (please select the whole line, at least the file path and the line number, and some string following it...!), and choose open_file_fromGrepRes from the Macro menu in Jedit X; this will open the file, and select the line. For example:
T01n0022_p0275b07(03)║其行平等,尊大自在,心念無畏。以一身化無數身,
This is the basic use of the droplet.
You can drag-&-drop more than one folder or more than one file at once on the droplet.
How to configure the settings:
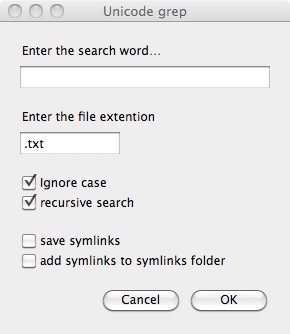
When you drop a file or a folder on unicode_grep.app, you will see a window like the following image:
This is a dialog window realized with a special application named “Pashua.app”, which is incorporated in the droplet (in its /Contents/Resources/ folder). Pashua.app is a creation by Carsten Blüm, and is a very useful tool for easy scripting. The dialog contains two text fields, and four checkboxes.
Two text fields:
• Enter the search word...: You can enter here any regex expression (we use here the standard egrep as the grep engine. So you can use such expressions as “大?自在天?”, etc.). The encoding is UTF-8. If nothing is entered here, the droplet will quit.
• Enter the file extension: You can enter here any file extensions. It can be for example “.txt”, “.pl”, “_utf8.txt”, “_u.txt”, etc. This option is only effective for folder search (it will have no effect if you drop a file, or files, on the droplet).
Four checkboxes:
• Ignore case: This has no effect if you search kanjis.
• recursive search: When this is checked, the search in folders will go through all the folder hierarchy; it has no effect for file searches.
• save symlinks: When this is checked, the droplet will not only do the usual search and display of the result in Jedit X, but it will also populate the folder named “grep_symlinks_folder”, in the same folder as the droplet itself, with symlink files of the matched files. This means that you can do further searches in these files if you drag-&-drop this “grep_symlinks_folder” on “unicode_grep.app”; in other words, you can simulate somehow a kind of “AND search”, and determine files containing more than one search word... Note that if the last checkbox, “add symlinks to symlinks folder” is not checked, the contents of the folder “grep_symlinks_folder” are each time deleted.
• add symlinks to symlink folder: When this is checked, symlink files of new matching files will be added to the grep_symlinks_folder; the previous symlink files will not be deleted.
Finally, there are two buttons:
• OK button: It will begin the actual search and display of the result.
• Cancel button: The droplet will quit without doing anything.
Supplementary notes:
A. You can use the recursive option to search files in nested folders inside one folder. For example, if you have a folder named "Taisho", in which you have folders such as T01, T02, T03... T85, you can search all the files in these sub-folders with the option recursive set to 1 (a search for the term "摩訶迦羅天" in all the CBETA Taisho files -- which finds 10 matched lines -- takes less than 10 seconds on my machine, a new iMac (2.8 GHz Intel Core i7). The time needed for the search seems to depend more on the number of hits than the number of files to be parsed... (in fact, the longest time is taken by Jedit X, to put the matched words in red color...)
You can drop also more than one folder or file onto unicode_grep.app. But you can perform more sophisticated searches if you use symlinked folders, and for that, you can use my another utility, named make_symlink.app that you will find in my page Make Symlink. For example, you can do something like the following:
1. Make a new empty folder where you want, and name it, for example, "agama";
2. Locate your folders T01 and T02, and drag and drop them onto the icon of make_symlink.app;
3. A folder choosing dialog will ask you to select the folder you want: you would select the newly created folder "agama".
That's all: you will have symbolic linked folders of your T01 and T02 folders inside your folder "agama"; you would drag and drop this folder, "agama", onto unicode_grep.app, to search all the files in your original T01 and T02 folders (the option recursive must be checked).
You can use the same technique to perform other kind of searches: for example, you would locate all the files whose translator is 鳩摩羅什, gather symbolic linked files of these files in a folder named "translations_kumarajiva", and search terms in these files, etc.
B. You should learn also how egrep works, and what wildcard characters can be used. Please have a look at for example:
http://www.wellho.net/regex/grep.htmlC. A final note of warning: I think unicode_grep.app is rather robust, but it is a simple AppleScript utility : you should NEVER search for words which may occur more than one or two thousands times. For example, NEVER try to search for "佛" in all the Taisho canon! That would crash certainly the application, and perhaps even the system!!
Download
Please download the package from this link (2.1 MB to download)..
I would appreciate any feedback, comments, bug reports or requests.
Thank you!
Go to Research tools Home Page
Go to NI Home Page
Mail to Nobumi Iyanaga
This page was last built with Frontier on a Macintosh on Sat, Jul 10, 2011 at 23:40:55. Thanks for checking it out! Nobumi Iyanaga