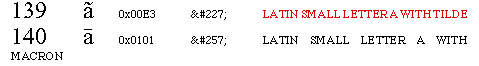Tables and converting scripts
first release :Dec. 19 2000
second release v. 1.1: Jul. 31 2001
third release version 1.2 (revised and enlarged: Feb. 15 2003)
Introduction
Now that Unicode begins to be used very largely in personal computing environment and Internet, it becomes important to be able to convert to Unicode files that have been created using "legacy codes". In general, this is not very difficult -- for the Mac environment, we can use utilities like Cyclone or TEC OSAX to do such tasks. It is even possible to convert to Unicode files of multilingual text (written using Apple's different language kits), if we use TEC OSAX (on these issues, please see my other web page "Unicode and MacOS, and Code converters"). But this becomes very hard when the texts to be converted use non standard fonts for transliteration of Asian languages, such as Times_Norman or Hobogirin, which have vowels with macron, etc.
Tables of correspondences
This is why I created tables of correspondences for some of the most used fonts among scholars: Times_Norman, Normyn and MyTimes (these two have the same glyphs: Normyn is a Roman font, and MyTymes is an Italic font), and Hobogirin (you will find many links to other Indic fonts at Indic language fonts at McGill University).
New (February 2003)
Since the last update, I found two very important resources on diacritical fonts and glyphs used for the transliteration of Indic languages:
In this latter site, you will find a manual for the URW Palladio HOT font, at http://home.t-online.de/home/ulrich.stiehl/pahotman.pdf, which is extremely instructive.
Added in July 2001
After having uploaded this page the first time on Dec. 19 2000, several persons requested a table for Appeal font, the font created by the International Research Institute for Zen Studies (IRIZ); while I could find a web page presenting this font at the IRIZ web site (http://www.iijnet.or.jp/iriz/irizhtml/tools/appeal.htm), I have been unable to find a link from which it can be downloaded. But this font is included in the ZenBase 1 CD-ROM which is distributed free of charge by the IRIZ (you can order the CD-ROM sending a self-addressed mid-size envelope and a US$ 10 bill [or 1000 yen or an international post coupon for the same amount of monay -- this is the shipping cost] to International Research Institute for Zen Studies, Hanazono University, 1-8 Tsubonouchi-cho, Nishinokyo, Nakakyo-ku, Kyoto 604-8456 Japan).
I asked the administrator of that web site the permission of distributing that font. He very kindly allowed me to do it. -- In fact, there is a web site from which the Appeal font can be downloaded: it is at http://www.indiana.edu/~asialink/fonts.html; but although it has the same name, the mapping of the characters are slightly different; and this may cause some confusion...
Examining Appeal font, I discovered that it uses some of the code positions which are normally used for control characters (ASCII decimal 1 to 32); it puts there some diacritical characters. As this font is a revised and modified version of the font Hobogirin, and of Norman family fonts, I examined also the same code points in these fonts, where I found some interesting characters. This is why I included these code points in my revised tables.
I found in the documentation which comes with the package of Appeal font a table of key combinations with which we can enter such or such characters. This table may be very useful in some cases; I created a new table of key combinations for the MacRoman characters. With this table, you should be able to enter characters of any code positions.
On the other hand, I have a font with many diacritical characters that I created myself, and I use personally: it is named "ITimesSkRom". As I am generally satisfied with it, I will distribute this font also, along with its conversion table to Unicode. Note that the space in this font is very large -- simply because I find the space in normal fonts too narrow. People may or may not like it. Replacing the space of ITimesSkRom with the space of other font, it is possible to make a "pseudo-kerning" of text.
New (added in February 2003)
After having bebun to use OS X.2 in September 2002, I realized that it is easy to use composite characters in Unicode. Composed characters are those characters which are composed of some predefined base character, with one or several "combining diacritical marks" (U+0300~036F). For example, a character like "LATIN SMALL LETTER A WITH MACRON AND TILDE" can be composed of U+0101 ("LATIN SMALL LETTER A WITH MACRON") and U+0303 ("COMBINING TILDE"). It is said, in "pahotman.pdf" that:The Unicode Consortium expects that intelligent word processors are capable of commposing all accented characters by base characters plus coposing diacritical marks via canonical stacking order. Therefore the Unicode Consortium does not intend to enlarge the number of Unicode-precomposed characters with the consequence that many accented characters used by indologists will never have official code points defined by the Unicode Consortium.This is why I revised all the font tables and added data for composit characters, refering to and following the recommended Unicode equivalents in the ISO 15919 home page at http://homepage.ntlworld.com/stone-catend/trind.htm. -- Note that there are still glyphs that cannot be composed in Unicode. For these, you should probably use some code points in the Private Use Area...
I added also new tables for three other fonts:
For these two latter fonts, I don't have any url for download site (BharatiTimes seems to be a bitmap font; it has some glyphs having two different code positions. I personally would not recommend the use of this font -- but people who use it may have problems to convert their files to Unicode...). If you need these fonts and cannot find them, please write; I can send them to people who want them.
- TimesCSXPlus TTF font (that you can download from ftp://bombay.oriental.cam.ac.uk/pub/john/software/fonts/csx%2B/)
- Minion-Indologist font
- BharatiTimes font
These fonts are specialized for transliteration of Indian languages, and of Japanese language. Times_Norman and Normyn/MyTimes don't have the LATIN CAPITAL LETTER O WITH MACRON, while Hobogirin, Appeal and ITimesSkRom have it.
The tables I created contain data for control characters, i.e. (some of the) characters from 1 to 31 (in hexadecimal representation: from 0x01 to 0x1F) and "higher ASCII" characters, i.e. characters from 128 to 255 (in hexadecimal representation: from 0x80 to 0xFF) for each font. For each character, there are 5 or 6 "fields":
- decimal number of the character position,
- the character's glyph itself (using the font),
- hexadecimal number of the corresponding Unicode character,
- decimal number of the corresponding Unicode character in HTML entity format,
- description of the glyph in the Unicode Standard way (the description is in red characters when the glyph and the character position are the same as those of the MacRoman encoding)
- optionally, mention that the predefined glyph does not exist in Unicode 3.0 (written in blue characters)
New
On the other hand, I added a "sharp" mark (#) before glyphs which are doubled in a same font. For example, there are two "MULTIPLICATION SIGN" in Hobogirin (at decimal 29 and 217); the first one (which is in the range of control characters) is preceded by "#" (my Perl scripts will skip the lines beginning with the sharp mark).
New in February 2003
In every case, when there is no predefined Unicode glyph but a composit glyph can be generated, I added a composit character code in the form: example:
0x016B+0x0306 ū̆ LATIN SMALL LETTER U WITH MACRON AND BREVEFor LATIN CAPITAL LETTER K WITH SMALL LETTER H AND MACRON BELOW BOTH and LATIN SMALL LETTER K WITH SMALL LETTER H AND MACRON BELOW BOTH which are in the positions decimal 200 and decimal 204 in TimesCSXPlus TTF font, I added exceptionally the equivalents in the Private Use Area, implemented in the font URW Palladio HOT (U+F147 and U+F148).
Here is an example:
The tables are named "Appeal -> Unicode", "Times_Norman -> Unicode", "Normyn -> Unicode", "MyTimes -> Unicode", "Hobogirin -> Unicode", "Times_Norman -> Unicode", "ITimesSkRom -> Unicode", "TimesCSXPlus TTF -> Unicode", "Minion-Indologist -> Unicode" and "BharatiTimes -> Unicode".
I used the book The Unicode Standard version 3.0 by The Unicode Consortium (Massachusetts, Addison-Wesley, January 2000) to make these tables. The work requires much attention, because it is not automatic; I had to compare each glyph of the fonts with the images in the tables of the book. The result may still contain errors. If you find any error, please let me know!
New (February 2003)
Unicode is now at version 3.2, adopted by the Mac OS X.2. You will find the documentation at ftp://ftp.unicode.org/Public/3.2-Update/ (but the book is still very useful, for browsing different glyphs).
I used also extensively a very useful (and free) utility to make these tables: UnicodeChecker 1.5.5 from Earthlingsoft (http://www.earthlingsoft.net/UnicodeChecker/)I made another table, which I called "MacRoman -> Unicode template". It contains data of characters from 0 to 31 and128 to 255 for the MacRoman encoding (I used the font Times). It can be used as a template to make similar tables for other fonts...
If you have a special font with glyphs similar to those of the fonts for which I made my tables (vowels with macron, etc.), you might want to make a copy of this template, select all its content, and change the font to your font. Then, comparing attentively the glyphs with those of my tables, you may be able to make your own table of correspondence -- at least as far as the glyphs of your font are included in the tables that I made. If it contains other glyphs, then, you will have to consult the above mentioned book The Unicode Standard, or its online version in pdf format (http://www.unicode.org/charts/index.html). You will have to consult especially the following charts:
- Latin-1 Supplement (pdf version );
- Latin Extended-A (pdf version );
- Latin Extended-B (pdf version );
- Combining Diacritical Marks (pdf version);
- Latin Extended Additional (pdf version )
(When I uploaded this page the first time, I did not know the existence of these online Unicode charts... I am grateful to my friends of the electronic discussion group "Pasokon-Toohoo-kenkyuu" of NiftyServe who provided me with these urls). Or, if you want, you can send me the font you use, and I will make the needed table.
The glyphs that are not included in Unicode 3.0 may be problematic. I thought it would be simpler to give the Unicode equivalences for the character positions in the MacRoman encoding, because anyway, these characters are used very seldom. But you may want to replace them with something like "0x????" and "&#????;"; if this is your solution, the converting scripts that you will find here should be changed somehow...
New (February 2003)
On this point, please see above, what I wrote about the "composit characters".I made these tables in Nisus Writer format and Tex-Edit Plus 4.0 format -- these are text files but the format information (with the font information) is stored in a sure way. You will have to install the needed fonts to see the glyphs. [The Tex-Edit Plus files have been generated based on the Nisus files. Please use the Nisus files to make other tools using Nisus macros or MacPerl scripts presented below in this page.]
I also made gif files of the glyphs with the character positions (see Appeal glyphs, Hobogirin glyphs, MacRoman glyphs, MyTimes glyphs, Normyn glyphs, Times_Norman glyphs, ITimesSkRom glyphs, TimesCSXPlus TTF glyphs, Minion-Indologist glyphs and BharatiTimes glyphs). This way, I think any user, even without the fonts, will be able to see the glyphs.
Download
- Tables in Nisus Writer format
- Tables in Tex-Edit Plus format
- Character glyphs in gif files
- Appeal font
- ITimesSkRom font
Scripts
1. Perl scripts
Now, I wrote also some Perl and AppleScript scripts which can be used with these tables, to convert texts written in these fonts to Unicode (please download and use MacPerl to run these scripts). The main Perl code for conversion is very simple. It supposes that an associative array of the characters to be converted and their corresponding Unicode character's hexadecimal value is made (and this can be made easily with the tables that I wrote). It will be something like this:%fontdata = ("Ä" => "00C4", "Å" => "00C5", "Ç" => "00C7", "É" => "00C9"...)
The Perl code will extract the first character from the string to be converted; it will examine if this character exists in the keys of the associative array; if this character exists, then it will "pack" the correspondent Unicode hexadecimal value to the binary value; otherwise (i.e. if the character position is in the range of "lower ASCII"), it will add 0x0000 to that character. Here is this code:
$unic = pack ("H*", 0x0000); while ($_) { $c1 = substr ($_, 0, 1); if(exists $fontdata{$c1}) { $unistr .= pack ("H*", $fontdata{$c1}); } else {$unistr .= $unic . $c1;} $_ = substr ($_, 1); }I added a routine that will convert the resulting Unicode string to UTF-8 string (I simply borrowed this routine from a converting script "Uni2UTF8" written by Nowral-san; see his Unicode page).
I wrote a Perl droplet that generates the needed associative array from a font table, and the Perl script itself: it is the droplet named "
generate_conv_script.dp". You will have to drag & drop the needed font table file on that Perl script; it will automatically generate the converting script for that font, in the same folder as the table, with the name "font_to_convert2unicode.pl" (the table file must be named "font_to_convert-> Unicode").
But in fact, I think that most of the time, we will have to deal with multi-font, multilingual text; this is why the scripts that are generated by the above mentioned script process not entire files, but a string that you will pass as the first argument, and, optionally, the word "Unicode" as second argument, if you want to get the Unicode string instead of UTF-8 string.
New (February 2003)
I wrote Perl droplets which convert to Unicode (UTF-8) entire files written in one of the fonts for which I wrote conversion tables (each of them is named "font_to_convert2unicode.dp"), and a Perl droplet that generates such converting droplets (named "generate_conv_droplet.dp").
- To use one of the converting droplets, you will drag-&-drop text files (they must be TEXT files -- so Nisus Writer files or Tex-Edit Plus files are OK, but MS Word files cannot be processed) written in one or another of these fonts on one of these droplets' icons.
- To use the droplet "generate_conv_droplet.dp", you will drag-&-drop a conversion table file on its icon; a new converting script will be generated and saved as a text file named "font_to_convert2Unicode.dp" in the same folder as the conversion table file. You will have to open that file in MacPerl, and save it as a droplet..
These scripts replace the old Perl droplet which could convert to Unicode (UCS-2) entire files written in one of the fonts for which I wrote tables ("conv to UCS-2 w/ spec fonts f"). -- I think the newer droplets are easier to use.
Download
- MacPerl
font_to_convert2Unicode.pl's andgenerate_conv_script.dp- MacPerl
font_to_convert2Unicode.dp's andgenerate_conv_droplet.dp
2. AppleScript scripts
Please note that the AppleScript scripts presented here will not work on OS X (probably because of some bugs in OS X.2 AppleScript and/or Style 1.9 AppleScript implementation for my script for Style; and also, because the OSAXen Text X amd System Misc are not [yet?] updated for OS X for my script for Nisus Writer... Sigh!)
I am preparing another set of scripts and tools which will be able to convert to UTF-8 multilingual text files in which one or another special font is used.
(Note added in February 2003)I wrote some AppleScript scripts which will pass the string as the first argument to the Perl scripts (those scripts named "
font_to_convert2unicode.pl"). The scriptable styled text editor named "Style" is particularly well equipped for our purpose, because it can convert Mac multi-style multi-font text to UTF-8 text with its own command ("UTF8 Text"), and it can get the font name of each style run. My script named"Convert to UTF-8 w/ spec fonts"must be placed in the folder "Style Scripts", inside the folder of Style. This script is fast enough to be used for practical use (a file of more than 100 KB can be converted in 5 or 10 minutes, depending on the speed of your machine). [As of February 2003, I rewrote this script, so that it works with MacPerl scripts (no longer MacJPerl), and also fixed a bug. -- With my new machine, PowerMac G4 867 MHz dual processor, I could convert a file of 130 KB in one minute. Conditions: OS 9.2.2, with Style 1.6 (with the latest version, 1.9.1 for Classic, I was unable to run this script...).]
I wrote another AppleScript script for Nisus Writer, named
"Conv to UTF8 w- spec fonts N". It requires several scripting additions:
one is TEC OSAX
and two others:
Text X and System Misc
These latter two are included in the package of an excellent scriptable editor named "QuoEdit" (version 0.641 and later); you can find it at http://hyperarchive.lcs.mit.edu/HyperArchive/Abstracts/text/HyperArchive.html, looking for "QuoEdit". You may need Jon's Commands also if you use OS earlier than 8.5 (download from Jon Pugh's site).
This script gets the selected text in Nisus Writer document, makes a new document with it, and convert it to UTF-8 text. But it is very slow, and is worth only for experimental use. It is an application, so that you have to launch it (i.e. double-click on its icon) to run it. You might want to put it in the Apple Menu Items folder, so that you will be able to launch it easily. [As of February 2003: even with the new machine, on the OS 9.2.2, this script is still very slow. On OS X.2, in Classic environment, this script doesn't run at all, because the OSAXen Text X and System Misc are missing...]
These AppleScript scripts have at the beginning this line:
This "property" defines the "Special fonts": the text written in one of these fonts will be converted by the Perl script. If you have any other "special font", you will need to add it in this list. The scripts assume that there are Perl scripts (in text files) named "Appeal2Unicode.pl", "Hobogirin2Unicode.pl", "Normyn2Unicode.pl", "MyTimes2Unicode.pl", etc., in a folder.property specialFonts : {"Appeal", "Hobogirin", "ITimesSkRom", "Normyn", "MyTimes", "Times_Norman"}
The second line of the scripts is:
property scriptFolder : ""This "property" defines the folder in which the Perl scripts are. When the scripts are executed for the first time, a file dialog will ask you to locate the "Script Folder" -- please select the folder in which there are the Perl scripts (scripts named "Appeal2Unicode.pl", "Hobogirin2Unicode.pl", "Normyn2Unicode.pl", "MyTimes2Unicode.pl", "ITimesSkRom2Unicode.pl", etc.); afterward, they will "know" where it is.
These are anyway experimental scripts. I hope however that they can be useful for you.
Download
- AppleScript script
Convert to UTF-8 w/ spec fontsfor the editor Style and MacPerl scriptsfont_to_convert2Unicode.pl's- AppleScript script
Conv to UTF8 w- spec fonts Nfor Nisus Writer and MacPerl scriptsfont_to_convert2Unicode.pl's
New (in February 2003)
3. Nisus macros and Perl scripts for conversions between different fonts and Unicode HTML entities
In this section, in the last release (in July 2001), I presented a set of Nisus macro and Perl script which generate Nisus macros that convert between different fonts. But they were too buggy (too difficult to make correct macro/script...). In this version, I decided to remove these macro/script, and instead, present a new set of macros/scripts, with which you can generate macros converting between different fonts and Unicode HTML entities. Using these macros, you can convert between different fonts as well..., and do other interesting things.There are two Nisus macros and two MacPerl scripts with which we can generate Nisus macros converting diacritical characters in such or such fonts to their Unicode HTML entity equivalents, or, in the reverse direction, converting Unicode HTML entities to the special diacritical characters in such or such fonts. Please note that these macros and Perl scripts are all in Nisus (normal) document files:
- the macro used to generate "your_font2htmlEntity" macro is the file named "font2html_entities macro";
- the Perl script used to generate "your_font2htmlEntity" macro is the file named "font2html_entities.pl";
- the macro used to generate "htmlEntity2your_font" macro is the file named "html_entities2font macro";
- the Perl script used to generate "htmlEntity2your_font" macro is the file named "html_entities2font.pl".
The Unicode HTML entity equivalent of "é" can be "é" (named entity) or "é" (entity in decimal notation) or "�x00E9;" (entity in hexadecimal notation). Here, I will use the second format (entities in decimal notation).
- To generate a macro which will convert diacritical characters of a font into their Unicode HTML entity equivalents:
- Open the conversion table of that font: for example "ITimesSkRom -> Unicode";
- Open the Nisus file named "font2html_entities macro" (be sure that the Nisus file named "font2html_entities.pl" is in the same folder as this file) [this order is important; the conversion table file must be behind the macro file];
- Launch MacPerl [MacPerl must be running before the macro is executed];
- Return to Nisus Writer; select all the text of the file "font2html_entities macro" and choose in the Macros menu "Execute Selection"
- A new macro file will open, and a new macro with the comment "//Replace All ITimesSkRom with Unicode-html-enities" at the top, will be generated. You can name this macro, for example "ITimesSkRom2htmlEmtity"
- To generate a macro which will convert Unicode HTML entities into diacritical characters of a font :
- Open the conversion table of that font: for example "ITimesSkRom -> Unicode";
- Open the Nisus file named "html_entities2font macro" (be sure that the Nisus file named "html_entities2font.pl" is in the same folder as this file);
- Launch MacPerl;
- Return to Nisus Writer; select all the text of the file "html_entities2font macro" and choose in the Macros menu "Execute Selection"
- A new macro file will open, and a new macro with the comment "//Replace All Unicode-html-enities with ITimesSkRom" at the top, will be generated. You can cut this macro and paste it into the previous macro file, and name it, for example "HtmlEntity2ITimesSkRom".
- To convert a file written with a font to a file written with another font: as an example, suppose that you want to convert a file written with Appeal into a file written with ITimesSkRom:
- Generate the converting macros for both fonts: "ITimesSkRom2htmlEmtity" and "HtmlEntity2ITimesSkRom" for ITimesSkRom, "Appeal2htmlEntity" and "HtmlEntity2Appeal" for Appeal.
- Open your target file and make a copy of it.
- Convert your file from Appeal to HTML entities using "Appeal2htmlEntity".
- Select all the text, and change the font to ITimesSkRom.
- Convert your file from HTML entities to ITimesSkRom, using "HtmlEntity2ITimesSkRom".
New (in February 2003)
4. Other use of Unicode HTML entities
A. Generate html files
HTML entities can be useful not only as this kind of "go-between" in the processus of conversion between different fonts. They can be used as well for creating HTML files (that is their main "raison d'être"!). If your file is NOT a multilingual file (i.e. if you have used only one font or fonts for MacRoman script to write your file), you can use Unicode HTML entities to generate easily HTML files that can be uploaded to your web site.I wrote a Nisus macro file named "
HTML Utilities macros" containing some macros to generate a very basic HTML markup.The most basic HTML markups are:
- Minimum header and footer
and- Line ending markup (<br> and <p>)
You can do these two markups with my macros "Minimum utf8 header/footer" and "<br> & <p> tag in Selection".
Other macros in this macro set can help you to mark up your document with some basic markup. One important thing you need to know is that the macro "Replace Special Chars" will replace the character "&" with "&" and the characters "<" and ">" with "<" and ">" -- so that if you use this macro, you must use it before using any other macros, and especially before using the macro "your_font2htmlEntity" macro.
When you have marked up your file, you can open it with a web browser, and/or upload it to your web site. Be aware that some web browsers (for example OmniWeb...) don't support these Unicode HTML entities.
B. Generate UTF-8 files
I wrote another simple MacPerl droplet named "htmlEntity2utf8.dp" which will convert to UTF-8 characters all Unicode html entities that are in a text file. So, if your file is NOT a multilingual file, you can drag-&-drop on the icon of this droplet your file, to generate a UTF-8 file. Of course, you can use it to generate UTF-8 HTML files as well (and the Unicode aware web browser, like OmniWeb or Safari, etc., will be able to display all your text).
C. Generate Unicode compatible RTF files
This method was first conceived by Kino. I followed his advise, and developed it somehow.You can use one or another RTF XTND filter to convert your Nisus files into rtf format files. I personally have three such filters: Claris RTF filter (that you can download from my site: click here); MacLink filter (which seems contained in the filter named "MacLinkPlus/Nisus Writer") and Mercury RTF filter. The one that seems to work the best is Claris RTF filter.You can use the conversion to Unicode HTML entities to convert multilingual files into multilingual and styled RTF files, with the correct Unicode characters. I could even convert multilingual files with footnotes (containing text in French, Japanese, Japanese and Sanskrit transliteration) into rtf files readable by MS Word for Windows. To do that:
- Open your target file in Nisus Writer, and run the macro "your_font2htmlEntity";
- If your MacRoman text contains Italic or Bold, etc. styles, it is better to change the font to some standard font, like Times at this step (your font may not contain Italic or Bold style glyphs when used in TextEdit -- even if these glyphs can be displayed in Classic applications [this is the case for ITimesSkRom]);
- If you intend to convert your file into rtf file readable in Windows environment, it is strongly recommended to change the MacRoman font to some font available in Windows also, for example Times New Roman.
- For non MacRoman text (Japanese for example), you should use only one font regardless of its shape (for example, Osaka may be good). In Windows environment, there is anyway no Japanese font of the same name...
- Do a "Save As...", and use an RTF filter to save the file as an rtf file (for files with footnotes, I used the RTF filter which displays "Export to RTF" in the pop-up menu, in the file save dialog; the two other RTF filters didn't work for me...);
- Open that file in Nisus Writer, as raw rtf code file (opening the file in normal way, either double-clicking on its icon in the Finder, or in the file open dialog in Nisus Writer without using any filter, or double-clicking on its name in the Catalog window, will open the file in this format).
- Open the "Find & Replace" window; set it to "PowerFind Pro" mode, then type:
Find \(&#\)\([0-9]+\)\(;\)And do a "Replace All";
Replace \\U\2\s\\uc0\s\\u\2\s
- If you want to convert your file into Windows, and if it contains text written in Japanese (or non MacRoman) font, you will have to make some tweaks at this step:
- Locate at the beginning of the rtf code the font table, and the font you have used. If it was "Osaka", you will need to locate the font definition of Osaka, which should look like:
You will have to change it to (something like) the following:{\f16384\fnil Osaka;}(the sequence "\'82\'6c\'82\'72 \'82\'6f\'96\'be\'92\'a9" is the rtf hexadecimal notation of "MS P明朝"); you may use as well the sequence "\'82\'6c\'82\'72\'82\'6f\'83\'53\'83\'56\'83\'62\'83\'4e", for "MS Pゴシック", etc.{\f16384\fnil \'82\'6c\'82\'72 \'82\'6f\'96\'be\'92\'a9;}- If you find in the raw rtf code the sequence "\lang9 \fbidi \ltrch " (note that there are three spaces in this sequence), you might want to delete it in all the text. Your "Find/Replace" expressions would be:
Find \lang9\s\fbidi\s\ltrch\sand do a "Replace All". -- But I think this is not really needed.
Replace- Open the file in TextEdit, or export it to a Windows machine, and open it with MS Word -- now, you should see all the text as it should be, with all your diacritical characters, kanjis if they are, and much of the original formatting (like Italic, Bold, line heights, indents, etc.) preserved. The font setting may be not correct; and if the text contains special diacritical characters, which are not in ordinary fonts, you should change the font to some special font, for example TITUS Cyberbit Basic (the same font works in Mac OS X and Windows). The footnotes are perhaps set as endnotes in MS Word; you can change it easily. And of course, you can add tab settings, edit your text as you like, at this step. -- And you can save the file as Unicode text file (in UTF-8 or UTF-16) if you want (but then, you will lose all the formatting information...).
But please be aware that if your original file contains any graphics, tables, etc., they will be lost in this conversion.
Download
- Nisus macros and MacPerl scripts to generate converting macros between different fonts and Unicode HTML entities; and a macro file containing converting macros themselves
- Nisus macro file
HTML Utilities macros- MacPerl droplet
htmlEntity2utf8.dp
I would be grateful if you could write me your comments, bug reports or suggestions for these tables and scripts.
Thank you in advance!
Go to Research tools Home Page
Go to NI Home Page
Mail to Nobumi Iyanaga
This page was last built with Frontier on a Macintosh on Sun, Feb 9, 2003 at 11:09:59 PM. Thanks for checking it out! Nobumi Iyanaga