 『運動学習にかかわる小脳の働き』
『運動学習にかかわる小脳の働き』体育の科学 2002年12月号 特集:脳の活性化と運動
兵庫医科大学リハビリテーション医学教室 道免和久 Kazuhisa Domen, MD, DMSc
北海道大学医療技術短期大学部作業療法学科 吉田直樹 Naoki Yoshida
兵庫医科大学リハビリテーション医学教室
〒663-8501 兵庫県西宮市武庫川町1-1
e-mail: domen@neuro-reha.org
『運動学習にかかわる小脳の働き』
体育の科学 2002年12月号 特集:脳の活性化と運動
兵庫医科大学リハビリテーション医学教室 道免和久 Kazuhisa Domen, MD, DMSc
北海道大学医療技術短期大学部作業療法学科 吉田直樹 Naoki Yoshida
兵庫医科大学リハビリテーション医学教室
〒663-8501 兵庫県西宮市武庫川町1-1
e-mail: domen@neuro-reha.org
はじめに
運動が上達することとは、つまり、運動学習を通して運動制御の精度を上げることである。したがって、運動学習と運動制御の仕組みの解明は、スポーツにおいても、運動障害者のリハビリテーションにおいても最も重要なテーマといえる。
運動制御の仕組みを説明する仮説として、従来より、仮想軌道制御仮説1)が有力であった。しかし、近年の計算論的神経科学computational neuroscience(脳の計算理論2))の進歩によって、仮想軌道制御仮説は否定され、「内部モデル」の概念を中心とした小脳による運動制御と学習理論が確立されてきた。本稿では、従来の運動制御仮説を概説した後に、運動学習における小脳のはたらきに関する理論を解説する。
仮想軌道制御仮説
随意運動の仕組みについての古典的な理論としては、フィードバック制御が最も一般的である。フィードバック制御では、目標とする位置と実際の位置がずれているとき、その誤差を修正するようにトルクを発生する。しかし、 体性感覚や視覚のフォードバックには、数10msec~100msec余りの時間遅れ(feedback delay)が存在するため、素早い運動の場合にはフィードバックによって誤差を修正しようとしても、正確な運動はできない。したがって、フィードバック制御は遅い簡単な運動にしか適用できず、日常の動作にみられる速いなめらかな運動の主たる制御方法とは考えられない。
速い運動を制御するためには、フィードバック情報に頼らずに、あらかじめ軌道を計算して、それに見合った運動指令を出力する前向き(フィードフォワード)制御が必要である。このようなフィードフォワード制御の理論として、仮想軌道制御仮説が提案されている。これは、運動指令が筋肉のばね特性を調節して、その釣り合い位置に向けて関節が動く、という仮説である。つまり随意運動は、経時的に変化する釣り合い位置(仮想軌道)に関節が追従することによって発現する。仮想軌道制御仮説には、α運動ニューロンの活性を調節しているという仮説(αモデル3))と、緊張性伸張反射の閾値を調節して筋長を制御しているという仮説(λモデル1))がある。両者の説は、反射のループを含むか否かという点で、本質的には異なるものであるが、共通する点は、脳が仮想軌道を作ることにより、身体がそれを追いかけることで随意運動が実現される、と考えていることである。
仮想軌道制御仮説では、脳は外部座標における軌道を計画するだけでよく、関節角やトルクなどの身体座標と外部座標との変換や、複雑な動力学的な計算をする必要がない。この仮説は、脳が複雑な計算をしているという立場をとらないため、脳の計算理論とは真っ向から対立していた。
仮想軌道制御仮説が正しいなら、腕が単純な軌道を描く時の仮想軌道は、実際の軌道の鋳型のように、単純な形をしているはずである。また、そのような制御を可能にするためには、理論的には運動中の腕のスティフネスstiffness(剛性)が高くなければならない。すなわち、運動中の腕は「かたく」制御されているはずである。この論争を決着させる研究がGomiら4)によって発表された。彼らはリーチング運動中のスティフネスを特殊な機器を利用して精密に計測した。その結果、運動中のスティフネスは予想されていたよりかなり低いこと、そして、仮想軌道が実現軌道と全く異なる複雑な形をしていることを見いだした。つまり、運動中の腕は、「かたい」制御ではなく、「やわらかい」制御を受けていることがわかった。また、脳は仮想軌道を直接計算して制御しているとは考えにくく、腕のモデルを脳内部にもつことによって、最適な軌道や運動指令の計算をしていると考える方が自然である。この事実から、古典的な仮想軌道制御仮説は、ほぼ否定され、小脳の内部モデルの学習を中心とした脳の計算論が趨勢となった。
小脳の内部モデルによる運動制御
小脳皮質は層状の均一な構造をしており、学習が可能な神経回路(ニューラルネットワーク)の集まりであると考えられている。小脳が学習機能をもつことは、伊藤ら5,6)によるプルキンエ細胞の長期減弱の研究等から知られている。
運動中の学習によって小脳は、筋骨格系への入出力関係、つまり、運動指令とその結果生じる軌道との関係の情報を蓄える2)。このような小脳内に保持される運動指令-筋骨格系の情報は内部モデルと呼ばれ、運動指令から軌道を出力する神経回路を順モデル、逆に軌道に見合った運動指令を出力する神経回路を逆モデルと呼ぶ。
Allen-Tsukahara7) の随意運動の制御モデルによれば、大脳皮質連合野が小脳外側部と大脳基底核の助けを借りて運動が計画された後、運動野から運動指令が脊髄を通して筋骨格系に送られる。体性感覚情報は、小脳傍虫部にフィードバックされ運動の修正を行う。
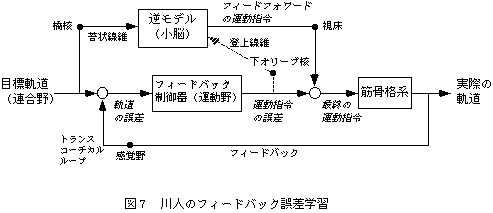
図1 川人のフィードバック誤差学習(川人2),Kawato8)を改変)
フィードフォワードによる運動制御とフィードバック誤差情報による運動学習部分からなる。運動の当初は、フィードバックの回路が重要な役割を果たすが、学習が進むにつれて、小脳を介したフィードフォワードの回路が主たる制御を行い、誤差信号は徐々に減っていく。
川人は、Allen-Tsukaharaの制御モデルを、神経回路の理論を応用して発展させ、以下のモデルを提案した(図1)。まず連合野から運動野に目標軌道が送られ、運動野から運動指令が脊髄へ伝えられる。実現した運動の情報は、大脳皮質を介するトランスコーチカルループによって運動野にフィードバックされる。このフィードバック回路でも運動は可能だが、フィードバック時間遅れなどの理由で、速いなめらかな運動はできない。そこで、小脳外側部-赤核系は、目標軌道と運動指令をモニターし、運動にみあった運動指令を出力する内部モデルを学習によって小脳に形成する。内部モデルとは、脳の外部(例えば、腕など)の入出力関係を表す概念である。例えば、ある運動指令を入力したときに出力される運動軌道の関係を順モデルと呼び、逆に、ある軌道を実現させるための運動指令を逆算するような関係を、逆モデルと呼ぶ。そして、この順逆モデルを合わせて、内部モデルと呼ぶ。内部モデルが存在すれば、目標とする軌道に見合った運動指令を簡単に計算することができる。内部モデルの学習では、小脳のプルキンエ細胞の可塑性と、プルキンエ細胞にシナプスをもつ登上線維の活動が重要である。すなわち、目標軌道と実現軌道の間の誤差は運動指令の誤差信号(教師信号)として下オリーブ核から登上線維を通って小脳プルキンエ細胞に伝達される。登上線維からの入力は、プルキンエ細胞に長期抑圧などのメカニズムによって可塑性変化(伝達効率の変化)をもたらし、運動の遂行毎に小脳の内部モデルの修正が行われる。学習がすすめば速いスムーズな運動がこの回路を用いて可能になる。これをフィードバック誤差学習feedback-error learning 8)といい、運動制御と運動学習を統合した理論といえる。フィードバック誤差学習における「フィードバック」とは、誤差情報をフィードバックすることによって内部モデルが修正され、徐々に正確なフィードフォワード運動指令を出力する内部モデルが生成されるように利用されることを意味している。
仮想軌道制御仮説の支持者たちは、制御すべき関節が1つ増えただけで、運動方程式の計算量が爆発的に増大することから、脳がそのような方程式を計算しながら運動を制御しているはずがない、と批判してきた。しかし、内部モデルがニューラルネットワークの形で存在すれば、目標軌道に見合った最適な運動指令を即座に計算できる。
フィードバック誤差学習理論が正しいことは、すでに多くの研究から支持されている。運動指令にあたるプルキンエ細胞の単純スパイク発火頻度の変化が理論の予測と一致していること9) が示され、登上線維入力によりプルキンエ細胞に生じる複雑スパイクが運動指令の誤差情報を表していること10) が報告されている。また、内部モデルが小脳に存在することを直接証明する注目すべき結果が最近報告された。Imamizuら11,12)は、機能的MRIによって、運動学習初期に小脳の広い範囲が活動し、学習後期にはその範囲が狭まることを示した。この事実のみでは、小脳が運動学習に関与しているが、内部モデルが小脳に存在するという証拠にはならない。そこで、運動学習中の小脳の領域を、その活動が誤差に比例する部分とそうでない部分に分け、その活動の変化を解析した。その結果、限局された範囲に内部モデルを反映する活動領域が存在することを証明した(図2)。
以上から、フィードバック誤差学習のスキームが、運動制御と学習の仕組みであることがわかる。
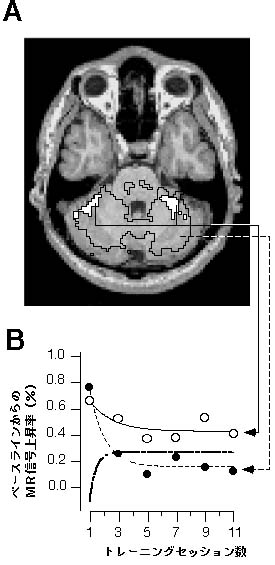 |
図2誤差を反映する活動と内部モデルを反映する活動(Imamizu 11) より) A:パソコンマウスの回転変換を学習する課題において、破線で囲んだ領域は、トレーニングセッションにおいて、トラッキング誤差と信号値の間で相関が有意であった領域。白く塗りつぶした領域は、誤差の統制実験において、内部モデルの活動と信号値のの間で相関が有意であった領域を示す。 B:破線と黒丸は、図2Aの破線で囲んだ領域における信号値の変化を、実践と白丸は、図2Aの白く塗りつぶした領域における信号値の変化を示す。一点鎖線の曲線と丸は、実線の曲線から破線の曲線を差し引いた値(内部モデルを表す)を示す。 |
内部モデルにより実現される「なめらかな」運動と「やわらかい」運動
小脳に内部モデルが学習によって獲得されることで、運動はどのように変化するのだろうか?運動制御の2つの側面に、なめらかさ(smoothness)と、やわらかさ(コンプライアンスcompliance, スティフネスの逆数)がある。そして、そのいずれもが、内部モデルの構築によって実現されると考えている。
内部モデルによって、目標とする軌道に最適な運動指令が生成される。したがって、目標軌道どおりの運動が可能になる。ここで、目標軌道はどのように生成されるのかが問題となる。仮想軌道制御仮説では、目標軌道の中でも最適な軌道は外部座標において躍度(加速度の時間微分)が最小となるように計画されると主張する。これは、躍度最小モデル13)と呼ばれるもので、実際のリーチング動作における手先の軌道をよく再現する。また、躍度の自乗の総和(時間積分)のような運動の最適化のための関数をのような運動の最適化のための関数を評価関数と呼び、運動の"なめらかさ関数"と言うこともできる。
ところが、その後の詳細な実験的検討から、最適軌道は外部座標におけるなめらかさを最大にするよりも、内部座標におけるなめらかさを最大にする、すなわちトルク変化14) や運動指令変化15) を最小にするように計画されていることがわかってきた。すなわち、最適な軌道は、身体外部空間における軌道のレベルでなく、身体内部空間において最適な軌道として生成されている。このような最適軌道の計算は、運動指令から軌道を計算する順モデルと、軌道から運動指令を計算する逆モデルの内部モデル対で行われている(順逆モデルに基づいた双方向性理論1))。
このように、内部モデルによる学習が進んだ最適な軌道は、なめらかさの指標を最大にするような軌道である。理論的には、おそらく運動指令のレベルでなめらかな運動が実現されると考えられるが、運動指令を直接計測することができないため、関節の動きから推定したトルク変化をなめらかさ関数として利用する場合が多い。トルク変化が最小となる軌道が、最も最適ななめらかな軌道であり、経由点を含む軌道や、外力が加わった場合の軌道も、実測値を理論値がよく再現することが証明されている(トルク変化最小モデル)。また、筋張力変化は、筋電図からローパスフィルタを通して変換した値から推定する。これは学習に伴う変化を追うには良い指標と考えている。
筆者ら16) は、健常人のリーチング動作で、運動学習にともなって各評価関数でみたなめらかさが増大すること、つまりよりなめらかな運動が実現されることを示した。また、運動障害患者に対して、各関数を利用して運動のなめらかさを定量的に計測し、障害の重症度の指標としての利用を提案した17) 。さらに、これらの関数とフィードフォワード運動の課題を利用して、なめらかさが増大するようなリハビリテーション訓練の方法を考案し、フィードフォワード訓練器18,19)として実用化しつつある。
図3(画像準備中)
図3リーチング運動の学習にともなうスティフネスの変化(Osu 20)より)
(a) リーチング動作において、課題が成功した試行のスティフネス指標の変化と誤差の変化の例。破線がデータを、実線がトレンドを示す。一定条件の課題に成功した試行だけを抽出しているため、誤差は低く、学習に伴う変化はない。ほぼ同じ軌道をとおって、ほぼ同じ関節トルクを発生しているにもかかわらず、各関節のスティフネス指標は学習とともに低下している。これは、同じ運動をよりリラックスして実行できるようになったことを示す。
(b) 誤差と肩関節のスティフネス指標の相互相関を、試行のラグによって図示した。正のラグにおける正の相互相関値は、ある試行の誤差と、その後の試行のスティフネス指標の間に、正の相関があることを示す。すなわち、ある試行で誤差が大きければ、その1から3試行程度後にスティフネスを上昇させる。一方、誤差が小さければ、その後の試行でスティフネスを低下させる。
(c) 学習過程におけるスティフネス、誤差、内部モデルの精度の関係を示した概念図。試行を繰り返すことにより、内部モデルの精度が上昇し、誤差とスティフネスは低下する。その過程において、誤差は短絡的にスティフネスに影響を与える。
一方、内部モデルが構築されるにつれて、「やわらかい」運動が実現されることは、最近になって証明された(図3)。経験的には、運動が上達するほど「肩の力が抜ける」とか、「力まずに」走ったら優勝した、など、余計な力が入らない「やわらかい」運動ほど良い運動である、というイメージがある。しかし、運動時間やその他の条件を一定にした上で、定量的にこの事実を証明した研究はなかった。Osuら20) は、リーチング課題において、運動学習とともに、筋電図を利用したスティフネスの指標が徐々に低下すること、すなわち、やわらかい制御になっていくことを証明した。また、試行を重ねる毎に、全体でみればやわらかい制御になるが、試行に失敗するとその後1~3回程度の試行はかたい制御に戻して成功しようと試みていることがわかった。
この研究から以下のような運動学習の戦略が見えてくる。すなわち、運動学習の初期は、内部モデルが不完全であるため、スティフネスを上げて運動に対応している。学習が進むにつれて、内部モデルが獲得されていくので、徐々にスティフネスを下げてもうまく運動ができるようになる。その途中で、試行に失敗すると一時的にスティフネスを上げて適応しながら、全体としては熟練した内部モデルによるやわらかい制御を学習していく。長年、仮想軌道制御仮説と内部モデルによる計算論的な制御との間で、論争が繰り広げられてきたが、真実はこれらの2つの理論が組合わさって運動が制御されていることになる。環境が不安定で学習が未熟な状態では仮想軌道的な制御を行い、予測可能な環境で、学習が進んだときは、内部モデルによる制御を行う、という脳の見事な運動制御の戦略が明らかになった21)。
最近の動向
内部モデルの概念は、言語などの高次脳機能や思考の領域にまで拡大されつつある22) 。運動との関連では、複合的階層的な運動学習を説明する「階層的多重順逆対モデル23) 」が提案され、このモジュールを多数個階層的に配置することにより、運動やコミュニケーション信号の認知にも拡大されようとしている。
おわりに
筆者は、運動障害患者のリハビリテーションに役立てようと、運動制御の基礎理論を、仮想軌道制御仮説の中心的な研究者Mark L Latash氏と、脳の計算論の第一人者である川人光男氏の両氏に学んだ。両者の考え方は全く異なっていたが、いずれも運動制御を別々の側面に鋭く迫る理論であった。真っ向から対立していた制御理論の両方が、学習の過程で時期を変えて出現する結果が出たとき、やや個人的な感情であるが、安堵したものである。今後は、計算理論を中心に、運動の本質がさらに浮き彫りにされていくだけでなく、認知科学の領域を含めて脳機能の解明が進むものと思われる。
文 献
1) Feldman, AG: Once more on the equilibrium-point hypothesis (λmodel) for motor control. J Mot Behav 18: 17-54, 1986
2) 川人光男:脳の計算理論, 産業図書,東京,1996
3) Bizzi E, Accornero N, Chapple W, Hogan N: Posture control and trajectory formation during arm movement. J Neuroscience 4: 2738-2744,1984
4) Gomi H, Kawato M: Equilibrium-point control hypothesis examined by measured arm-stiffness during multi-joint movement. Science, 272: 117-120, 1996
5) Ito M, Sakurai M, Tongroach P: Climbing fibre induced depression of both mossy fibre responsiveness and glutamate sensitivity of cerebellar Purkinje cells. J Physiol London 324: 113-134,1982
6) Ito M.:Mechanisms of motor learning in the cerebellum.Brain Res.15;886(1-2):237-245,2000
7) Allen GI & Tsukahara N: Cerebrocerebellar communication systems. Physiol Rev 54: 957-1006, 1974
8) Kawato M, Furukawa K, & Suzuki R. A hierarchical network model for motor control and learning of voluntary movement. Biol Cybern 57: 169-185, 1987
9) Shidara M, Kawano K, Gomi H, Kawato M.: Inverse-dynamics model eye movement control by Purkinje cells in the cerebellum.Nature 365(6441):50-52, 1993
10) Kobayashi Y, Kawano K, Takemura A, Inoue Y, Kitama T, Gomi H, Kawato M.:Temporal firing patterns of Purkinje cells in the cerebellar ventral paraflocculus during ocular following responses in monkeys II. Complex spikes.J Neurophysiol. 80(2):832-848, 1998
11) Imamizu H, Miyauchi S, Tamada T, Sasaki Y, Takino R, Putz B, Yoshioka T,Kawato M.Human cerebellar activity reflecting an acquired internal model of a new tool.Nature. 2000 403(6766):192-5.
12) 今水寛: 小脳と運動学習 fMRIによる研究. 脳の科学22(10): 1087-1093(2000.10)
13) Flash T & Hogan N: The coordination of arm movements: An experimentally confirmed mathematical model. Journal of Neuroscience 5: 1688-1703, 1985
14) Uno Y, Kawato M, Suzuki R: Formation and control of optical trajectory in human multi-joint arm movement - minimim torque-change model. Biological Cybernetics. 61: 89-101, 1989
15) Kawato M: Trajectory formation in arm movements: minimization principles and procedures. In Zelaznik HN (ed.) Advances in Motor Learning and Control. Human Kinetics Publ. Chanpaign Illinois, 1996
16) Domen K, Osu R, Yoshioka T, Kawato M , Decrease in optimal performance indices for trajectory planning during motor learning. 27th Annual Meeting Society for Neuroscience, 1997, New Orleans
17) Domen K, Rieko Osu, Yoshida N, Kawato M , Evaluation of motor function using optimal performance indices for trajectory planning in hemiparesis patients. 28th Annual Meeting Society For Neuroscience, 1998, Los Angels.
18) Domen K., Osu R., Kawato M., Yoshida N., Kawato M. , Feedforward movement exercise reconstructing the internal model in the cerebellum in poststroke hemiparesis. Progress in Motor Control II, State College, USA, 1999
19) 道免和久、大須理英子:【リハビリテーション医学の進歩と展開】片麻痺上肢のフィードフォワード運動訓練(解説/特集)、現代医療32:77-82、2000
20) Osu R, Franklin DW, Kato H, Gomi H, Domen K, Yohioka T, Kawato M: Short- and Long-Term Changes in Joint Co-Contraction Associated with Motor Learning as Revealed from Surface EMG. J Neurophysiol 88:991-1004,2002
21) 川人光男:運動学習 巻頭言「運動学習から認知へ」.バイオメカニズム学会誌25 (4): 151, 2001
22)川人光男: 小脳外側部の内部モデル, ヒトの知性の計算エンジン: 想像, コミュニケーション, 言語, 思考, 意識, 別冊数理科学, 特集: 脳科学の最前線-数理モデルを中心として, サイエンス社, pp194-208,1997
23) 川人光男, 銅谷賢治, 春野雅彦: ヒト知性の計算神経科学 第4回 多重順逆対モデル(モザイク). 岩波科学. 70, 2000, 1009-1017.
文 献
1)大須理英子、道免和久、五味裕章、吉岡利福、今水寛、川人光男:運動学習時における筋活性の変化、信学技報、NC96-139、201 - 208、1997
2)大須理英子、道免和久、五味裕章、吉岡利福、今水寛、川人光男、筋電図による運動学習時の腕の硬さの変化の推定、第20回日本神経科学学会、1997
3) 川人光男:脳の運動学習. 日本ロボット学会誌 13:11-19, 1995
4) Kawato M, Furukawa K, & Suzuki R. A hierarchical network model for motor control and learning of voluntary movement. Biol Cybern 57: 169-185, 1987
5) 川人光男:脳の計算理論, 産業図書,東京,1996
6) Domen K, Osu R, Yoshioka T, Kawato M , Decrease in optimal performance indices for trajectory planning during motor learning. 27th Annual Meeting Society for Neuroscience, 1997, New Orleans
7) 道免和久、大須理英子、川人光男、吉田直樹、千野直一、小脳の内部モデルの再構築をめざした片麻痺上肢のフィードフォワード運動訓練の検討. 第36回 日本リハビリテーション医学会学術集会、1999
8) Flash T & Hogan N: The coordination of arm movements: An experimentally confirmed mathematical model. Journal of Neuroscience 5: 1688-1703, 1985
9) Uno Y, Kawato M, Suzuki R: Formation and control of optical trajectory in human multi-joint arm movement - minimim torque-change model. Biological Cybernetics. 61: 89-101, 1989
10) Kawato M: Trajectory formation in arm movements: minimization principles and procedures. In Zelaznik HN (ed.) Advances in Motor Learning and Control. Human Kinetics Publ. Chanpaign Illinois, 1996
11) 大須理英子、宇野洋二、小池康晴、川人光男: 運動軌道データから計算される評価関数による軌道計画規範の検討. 医用電子と生体工学 vol. 34 394-405, 1996
12) Domen K, Rieko Osu, Yoshida N, Kawato M , Evaluation of motor function using optimal performance indices for trajectory planning in hemiparesis patients. 28th Annual Meeting Society For Neuroscience, 1998, Los Angels.